
Zipkin with Spring Boot

Have you ever wondered how does loggin happen in a microservice architecture. Where having logs for each and every service would just make it difficult as the services would increase. To solve the problem,we have tools like Zipkin which can be integrated with major frameworks and be used to keep trace of requests and measure the latency for the services. In this tutorial we will be covering the following topics:
- What is Zipkin and why do we need Zipkin?
- How to integrate Zipking with spring boot application?
- Running microservices in spring boot and sending logs request to Zipkin
- Analyzing the results in Zipkin UI
So, lets get started with our first topic.
What is Zipkin and why do we need Zipkin?
Have you wondered how would you connect the various logs within your microservices? Such that whenever a user/client hits one of your microservice and it calls a set of other microservices and just like a good developer you log all the requests to the logs. But you still don’t know what was the latency related to the microservice, what microservice was not hit and what was the error that occurred. To simplify, let us consider the following UML diagram of a simple microservice.
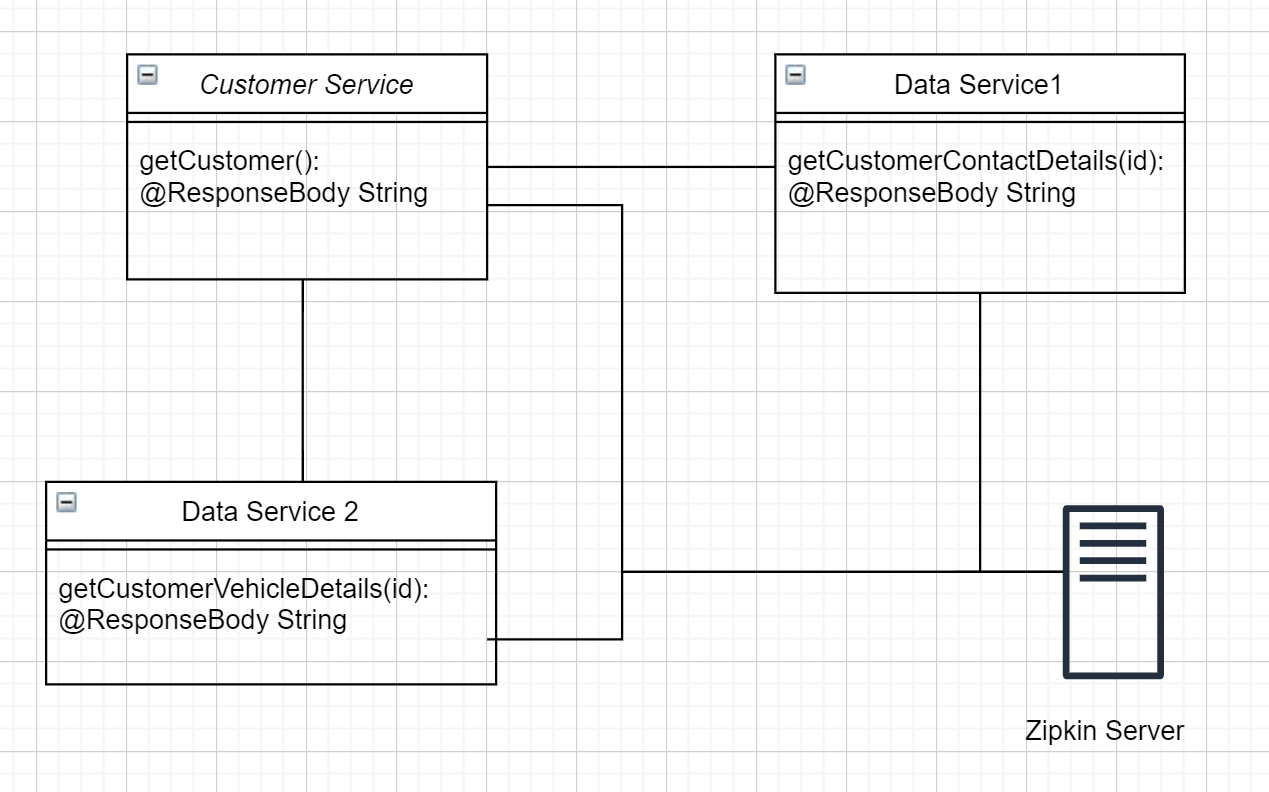
Within the above UML diagram, you can see that there is a CustomerService, DataService1 and DataService2. This is a very common example of microservice architecture and we see that all these services are connected to a zipkin server.
This is where zipkin comes in, Zipkin is a tracing system that is used in a distributed architecture or system. It also logs the time for each service, helping us to analyze which service is taking more time, thereby giving more time to analyze where you can improve the efficiency of the system.
How Zipkin does is, it has a trace ID and span ID. Whenever a client comes to your system, a trace ID is issued, which remains unique to the entire request and span ID remains unique to the microservice that is being used. So, now if you want to trace your request against a specific user, you can follow the trace ID which Zipkin presents in a visualized manner as well.
Now we have a brief understanding of zipkin, we can create a zipkin server to which these microservices would then send request. To set up the Zipkin server, run the following commands on the
Once we have the instance of Zipkin running on http://localhost:9411/zipkin/ the next step is to integrate it with Spring boot application. If we see our command prompt we get
The above screenshot shows that the zipkin server is up and running
Integrating Zipkin with spring boot application
To integrate Zipkin with Spring boot, we need to add Zipkin and Spring Sleuth dependency to our project. Once the dependencies are added to the project, we need to configure our application property to set our sampler size as 1 for Zipkin. Sampler is a way to keep track of how many traces (samplers) to keep against each request. You can find more about Spring Cloud Sleuth <a href=”https://spring.io/projects/spring-cloud-sleuth”>here</a>
The property file and the pom.xml file is shown below:
Now once, we have the dependency set up in our project, we need to create the microservice that we discussed in the UML diagram above. We will be using three microservices: dataService1, dataService2 and customerService. DataService1 has the API that gives the result related to the contacts. DataService2 has the API that gives the result related to the Vehicle. In dataservice2, we have added a latency which we will see in the Zipkin output and use it to analyze our service. We also have customerservice that calls both these services and returns back the result.
The code for the all the API is shown in the following gist:
Now, when we call the API using postman, we get the following output:
 The above screenshot shows the result of GET request when we hit dataService1
The above screenshot shows the result of GET request when we hit dataService1
 The above screenshot shows the result of GET request when we hit dataService2
The above screenshot shows the result of GET request when we hit dataService2
 The above screenshot shows the result of GET request when we hit customerService
The above screenshot shows the result of GET request when we hit customerService
This means that we have done our setup for the APIs correctly, next we want to see if these results are registed to Zipkin or not.


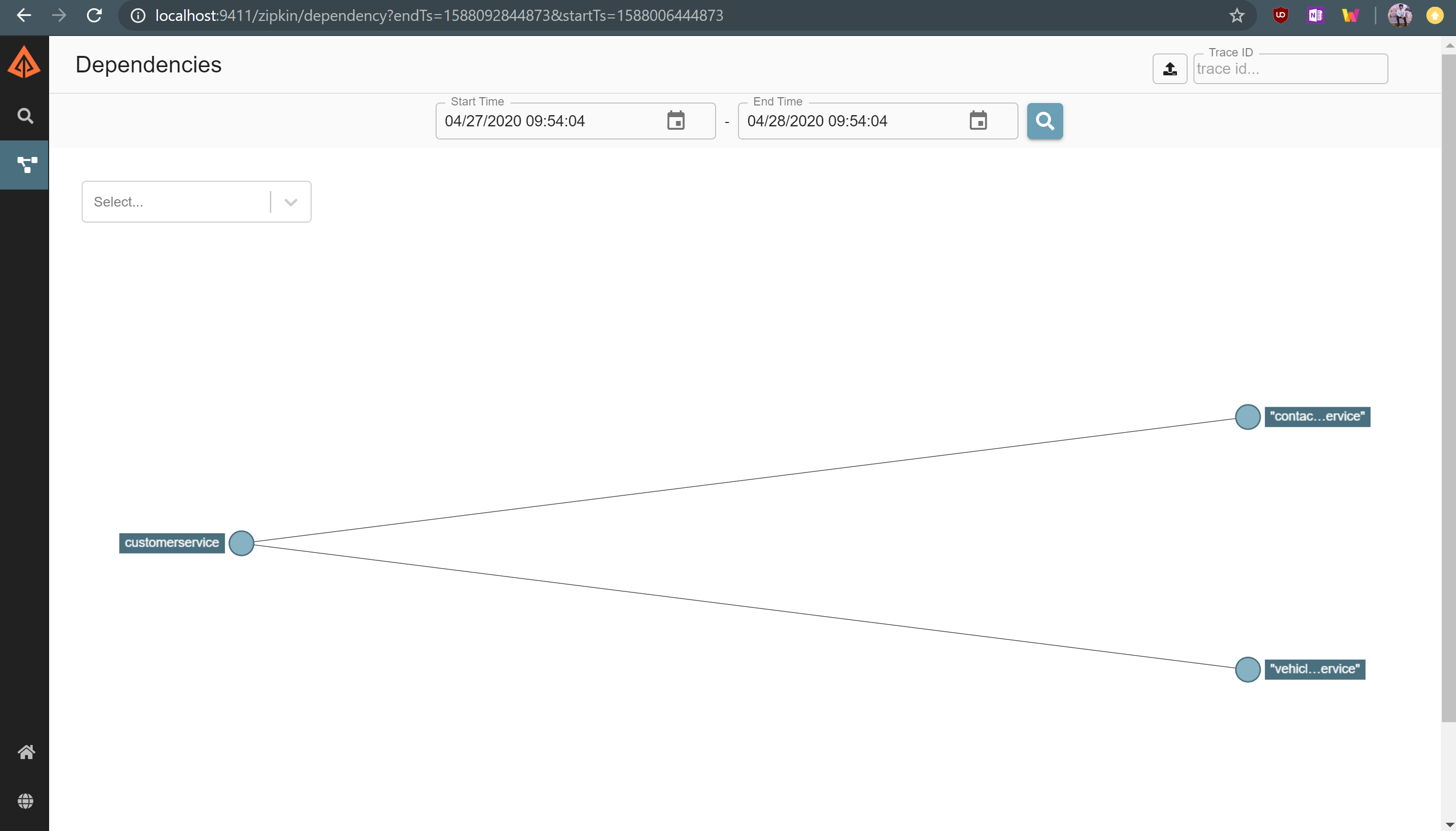
Analyzing results from Zipkin
From this we can see we have a centralized logging system such that each request has one trace ID which is unique for each request. We also have a span ID that is unique for each service.
From the above screenshot related to Zipkin, we see that the customer service takes 3.116 sec to execute, out of this the contact details take 3.016 sec to execute and that is where we had added our latency. The vehicle service takes only 7.29 ms since it didn’t have any latency code.
Github Code
You can get the complete code from github in my Spring Boot Series: DataService1, DataService2,CustomerService