Realtime LLM Inference on Standard GPUs 3k tokens/s per request
News Source : Blog.kog.ai
News Summary
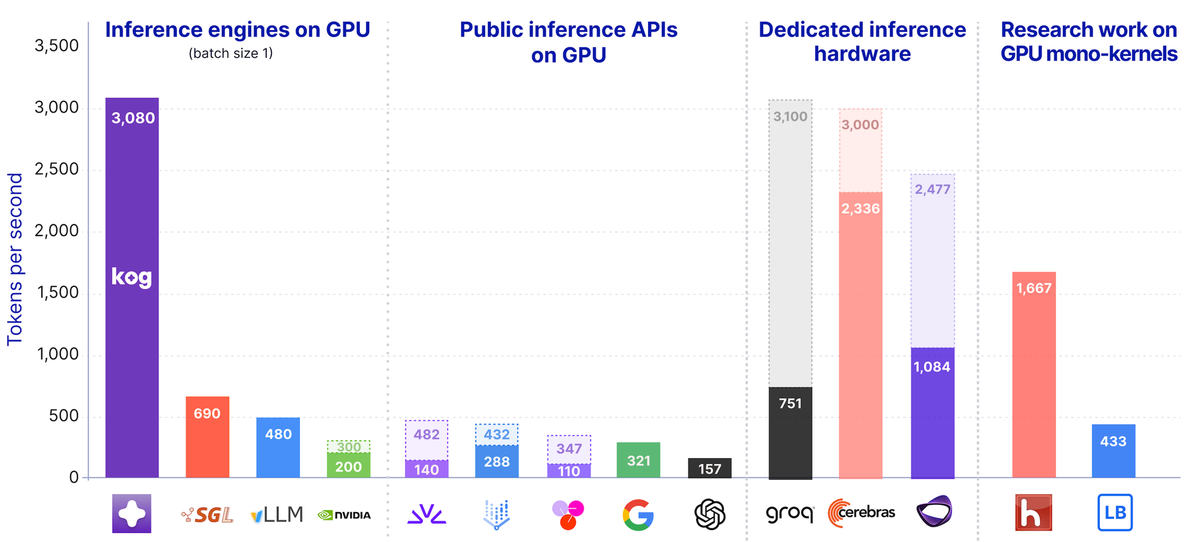
- Kog.ai shows that AI inference on GPUs can be super-fast, reaching the speed regime of dedicated inference hardware cards when optimizing the whole software stack.
- Memory bandwidth is the primary bottleneck for fast token generation (and GPU nodes have plenty) As agents become more autonomous, the productivity frontier shifts from intelligence alone to intelligence × iteration speed.
- The best agents will generate more useful tokens, reason more, and perform more tool calls, tests, and revisions inside the same wall-clock budget.




















